Does GPT-5.2 Change the Paradigm?
From Brief Conversations to Real Execution
The world of Artificial Intelligence (AI) is accustomed to grand promises. Over the past two years, most new models felt like incremental improvements: a little faster here, a little smarter there. Despite the hype surrounding previous versions of ChatGPT, such as GPT-4 and its various updates, many professionals felt something was missing. Chatbots were excellent for brainstorming and conversation, but they often proved fragile when required to complete actual end to end work.
The significant news regarding GPT-5.2 is not merely higher benchmark scores. The core promise of this model is a fundamental shift: a transition from small talk to execution. OpenAI positions GPT-5.2 as a model for professional labor and long, multi-step tasks. This includes creating complete artifacts like tables, presentations, and code, as well as the end to end execution of real workflows. This marks the end of the era of casual AI conversations and the beginning of reliable professional partnership.
If you want to apply this in practice, explore our service for AI chatbots for websites and social media. These tools automate inquiries, provide personalized recommendations, and integrate with external systems.
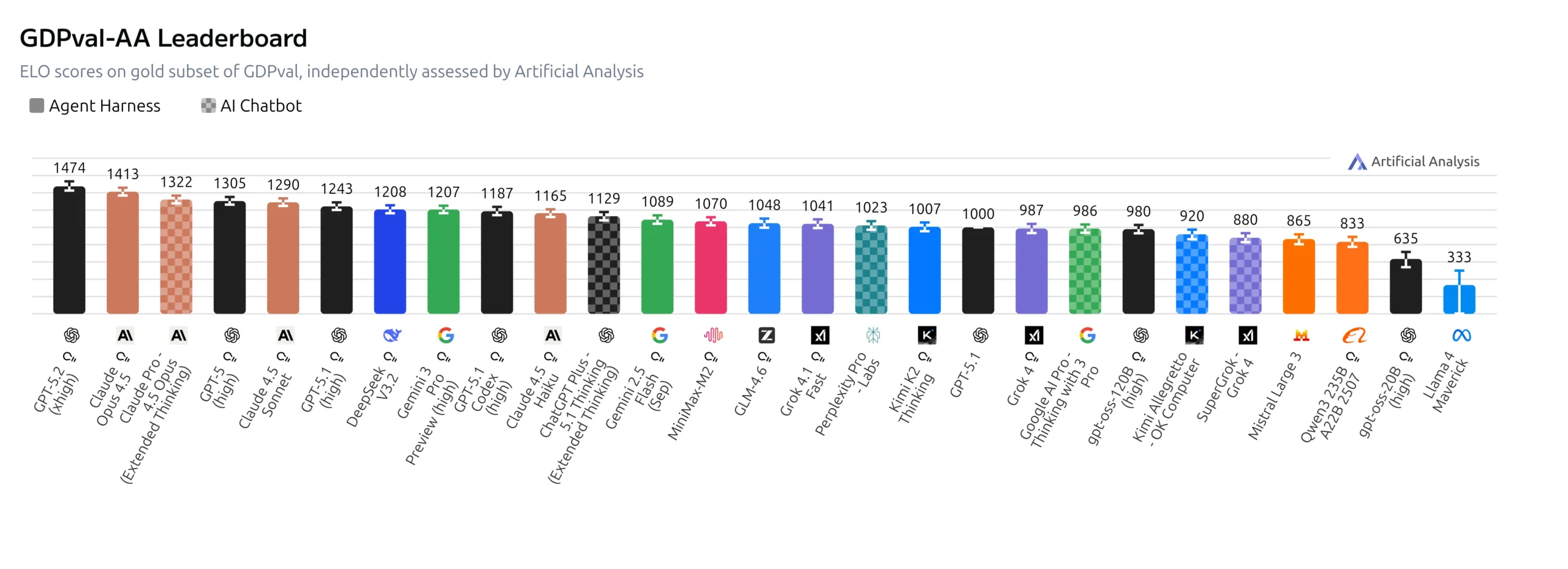
This is an independent assessment by Artificial Analysis based on the public gold subset of GDPval. The results are presented as an ELO metric calculated from blind pairwise comparisons between solutions using the Bradley-Terry model, featuring bootstrapped confidence intervals. This serves as a useful guide when seeking an independent view of the quality of real deliverables rather than just internal benchmarks.
The Innovations Under the Hood of GPT-5.2
Multimodality and Spatial Intelligence
One of the most impressive enhancements in GPT-5.2 is its image understanding, known as spatial intelligence. The model more accurately recognizes where elements are located within a frame and how they are positioned relative to one another. This is critical for tasks such as UI audits, screenshot analysis, diagrams, and visual reports.
Important clarification: this vision improvement refers to the perception and analysis of images, and it is not necessarily a guarantee of how image generation will always appear.
The Neon Sign Mobigrab Test: Passed with Honors
To test image generation, specifically whether the model can render legible text in a complex scene involving neon, rain, and reflections, I provided the following prompt for a night street with neon signs and specific text:
Generate a cinematic photo of a rainy futuristic street at night. A large, glowing neon sign in cyan and pink reads: ‘GPT-5.2 IS ONLINE’. Below it, a smaller yellow sign says: ‘System Fully Operational’. Realistic textures, puddles reflecting the text, 8k resolution.
The Result:

As seen in the image above, GPT-5.2 did more than just draw a picture. It rendered the text “GPT-5.2 IS ONLINE / SYSTEM FULLY OPERATIONAL” without a single spelling error. Even more impressive is that the model understands the physics of light. The reflections in the puddles correspond correctly to the light source, creating a photorealistic effect. This makes it a powerful tool for designers who need rapid mockups featuring specific messaging.
Enhanced Logic and Reasoning
GPT-5.2 provides superior stability for multi-step tasks through controlled reasoning effort. This includes the new “xhigh” setting, which intentionally trades a portion of speed and cost for deeper processing and higher quality final results.
In real world intellectual labor tasks (GDPval) evaluated by expert judges, GPT-5.2 Thinking either wins or matches top professionals in 70.9% of comparisons. These tasks involve the creation of presentations, spreadsheets, and other finished artifacts. OpenAI further notes that for these specific assignments, the model produced outputs at over 11x the speed and less than 1% of the cost of human experts. It is specified that these speed and cost estimates are based on historical metrics, and actual performance within ChatGPT may vary.
Unmatched Memory Window (Context Window)
One of the most significant steps forward is the handling of long context. OpenAI reports that GPT-5.2 Thinking sets a new benchmark in long-context reasoning and achieves leading performance on MRCRv2, which measures the ability to integrate information scattered across lengthy documents.
Notably, OpenAI emphasizes that this is the first model to reach near 100% accuracy on the 4-needle variant of MRCR up to 256k tokens. Detailed benchmarks also show 89.8% on BrowseComp Long Context at 256k, supporting the claim of more stable performance during very long context operations.
In practical terms, this means more reliable work with voluminous materials such as contracts, reports, transcripts, and multi-file projects, with a lower risk of “silently dropping” important details. However, human verification remains a standard rule for critical cases.
Speed and Agentic Capabilities for Developers
For developers, OpenAI introduced the apply_patch tool, which allows for structured changes (diffs) to a codebase instead of full rewrites. In testing, the “named function” implementation reduced the failure rate of apply_patch by 35%, significantly increasing reliability during multi-step edits.
Practical Applications and Real-World Examples
GPT-5.2 is designed to be a dependable executor across various professional fields:
Marketing: From initial concepts to completed campaigns.
The model can create a comprehensive marketing campaign plan coordinated across various formats, from text and visuals to spreadsheets for scenario modeling. It synthesizes information from scattered sources and transforms it into a unified, coherent strategy ready for execution. To apply this in real campaigns and pages, see our service for Content Marketing & Copywriting.
Law: Reliable Processing of Complex Cases
Legal professionals can upload a complete case file without worrying that the model will forget facts or arguments introduced at the beginning while drafting a plea or analyzing precedents. This ensures high accuracy and completeness in legal analysis.
Programming: Code Generation and Direct Editing
Through integration with platforms like Microsoft Foundry and GitHub Copilot, GPT-5.2 generates code and writes tests and deployment scripts with significantly fewer iterations and errors. Its ability to perform direct code editing is key to developer efficiency.
Visualization: Clean Text within Images
While it still trails specialized models in artistic rendering, GPT-5.2 excels in the clean and clear rendering of text within the image itself. This makes it ideal for infographics, UI elements, and presentations.
Comparison: GPT-5.2 vs. Its Predecessors
From “Drafts” to “Artifacts”: The Evolution of Reliability
While previous AI models similar to ChatGPT were strong at generating ideas and drafts, GPT-5.2 is designed to deliver finished products ready for direct use. This marks a transition from a brainstorming assistant to a task executor.
Memory and Context: An End to “Forgetting”
Unlike GPT-4 or GPT-5.1, which often “forgot” portions of long files or conversations, GPT-5.2 maintains stable memory without the “silent dropping” of facts during long-context tasks. This means it can process entire books, legal files, or codebases without losing information.
Reduced Hallucinations and Improved Accuracy
OpenAI reports that across a set of de-identified ChatGPT queries, responses with errors were 30% relative less frequent compared to GPT-5.1 Thinking. In practice, this translates to more dependable answers for daily professional work. This significantly improved accuracy is critical for professional applications where errors can have serious consequences.
Real-Time Editing and Autonomy
Previous models required new prompts for every edit, which often interrupted the workflow. GPT-5.2 reduces the need for repeated iterations by maintaining a more stable context and making more precise corrections within a single session. This allows for smoother operations and faster iterations.
Conclusion: The Future of AI with GPT-5.2
GPT-5.2 is not just another version of ChatGPT. The primary focus is the shift from “talking about work” to actual execution, featuring better stability in multi-step tasks, longer context, and more reliable results. For professionals, this means fewer iterations, fewer omissions in lengthy materials, and more practical deliverables.
Do you want GPT-5.2 for your business? We implement AI chatbots for websites and social media, handling inquiries, recommendations, automated services, and integrations with external systems.
Frequently Asked Questions (FAQ) about GPT-5.2
What distinguishes GPT-5.2 from previous versions like GPT-4?
GPT-5.2 is positioned as a model for professional work and multi-step tasks, including the creation of complete artifacts such as tables, presentations, and code. It supports an extensive context window of up to 256k tokens. OpenAI reports that error-related responses were 30% relative less frequent compared to GPT-5.1 Thinking across de-identified ChatGPT queries.
What does “spatial intelligence” mean in GPT-5.2?
Spatial intelligence refers to improvements in vision (image understanding) where the model more accurately recognizes the positioning and arrangement of elements within a frame. This is essential for UI audits, screenshot analysis, diagrams, and visual reports.
Important: This refers to the perception and analysis of images. Legible text in generated images depends on specific generative results and is not a universal guarantee.
Can GPT-5.2 edit code directly?
Yes, with the new apply_patch feature, GPT-5.2 can directly edit code through structured changes (diffs), reducing errors by 35% and accelerating the development process.
How reliable is the memory of GPT-5.2 with long documents?
GPT-5.2 demonstrates nearly 100% accuracy in tests involving volumes up to 256k tokens, maintaining a stable context from beginning to end without “silently dropping” information.
For which professional tasks is GPT-5.2 most suitable?
GPT-5.2 is exceptionally well-suited for tasks requiring finished results and high context: marketing materials and plans, legal analysis of voluminous documents, code development and refactoring, UI/UX analysis of screenshots, and visual reports.



